Memahami Bias dan Variance dalam Machine Learning
 02 Juli 2024
02 Juli 2024
Dalam machine learning, konsep bias dan variance adalah dua komponen utama yang mempengaruhi performa model. Memahami dan mengelola bias serta variance adalah kunci untuk membangun model yang dapat menghasilkan prediksi yang akurat dan dapat diandalkan. Artikel ini akan menjelaskan apa itu bias dan variance, bagaimana keduanya mempengaruhi model machine learning, serta strategi untuk mengoptimalkan keseimbangan antara keduanya.
Apa itu Bias dalam Machine Learning ?
Bias mengacu pada kesalahan yang dihasilkan oleh asumsi-asumsi yang ada dalam model machine learning. Bias tinggi terjadi ketika model terlalu sederhana dan tidak mampu menangkap kompleksitas dari data. Ini sering disebut sebagai underfitting. Model yang mengalami underfitting biasanya memiliki performa buruk baik pada data pelatihan maupun data uji.
Contoh Bias Tinggi
Misalkan kita memiliki data yang menunjukkan hubungan non-linear antara dua variabel, tetapi kita menggunakan model linear (misalnya regresi linear sederhana). Model ini akan gagal menangkap pola non-linear yang ada dalam data, sehingga menghasilkan prediksi yang buruk.
Apa itu Variance dalam Machine Learning ?
Variance mengacu pada sensitivitas model terhadap fluktuasi dalam data pelatihan. Variance tinggi terjadi ketika model terlalu kompleks dan menangkap noise dari data pelatihan, yang mengakibatkan performa buruk pada data uji. Ini sering disebut sebagai overfitting. Model yang mengalami overfitting biasanya menunjukkan performa sangat baik pada data pelatihan namun buruk pada data uji.
Contoh Varianve Tinggi
Jika kita menggunakan model yang sangat kompleks (misalnya, pohon keputusan dengan kedalaman yang sangat tinggi) untuk data yang sebenarnya sederhana, model ini akan terlalu menyesuaikan diri dengan data pelatihan, termasuk noise atau anomali, sehingga gagal dalam generalisasi ke data baru.
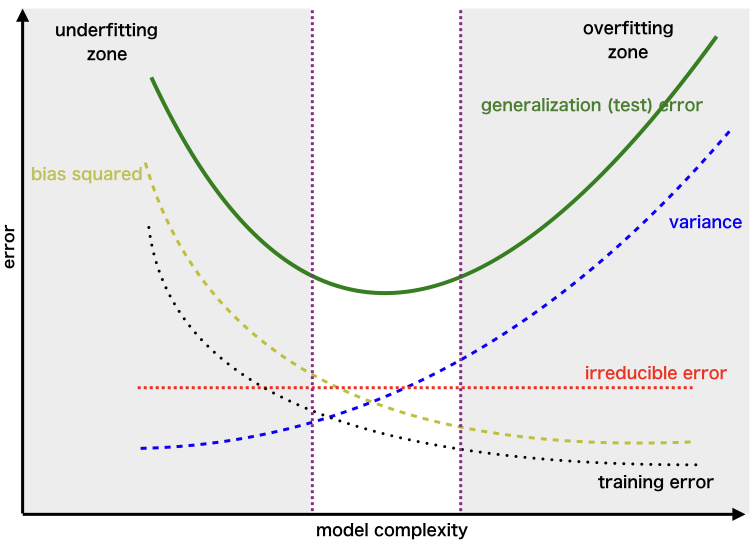
Trade-off antara Bias dan Variance
Dalam machine learning, ada trade-off antara bias dan variance. Meningkatkan kompleksitas model akan mengurangi bias tetapi meningkatkan variance, dan sebaliknya. Tujuan utama adalah menemukan keseimbangan yang tepat di antara keduanya untuk meminimalkan total error (kesalahan total).
-
Bias tinggi dan variance rendah: Model sederhana yang cenderung underfitting.
-
Bias rendah dan variance tinggi: Model kompleks yang cenderung overfitting.
-
Bias dan variance seimbang: Model yang mampu generalisasi dengan baik ke data baru.
Teknik Mengelola Bias dan Variance
1. Cross-Validation
Menggunakan teknik cross-validation seperti k-fold cross-validation dapat membantu mengevaluasi performa model dengan lebih baik dan mencegah overfitting.
2. Regularisasi
Regularisasi (misalnya L1, L2) menambahkan penalti terhadap kompleksitas model, yang dapat membantu mengurangi variance tanpa meningkatkan bias secara signifikan.
3. Ensemble Methods
Metode ensemble seperti bagging (misalnya Random Forest) dan boosting (misalnya AdaBoost) mengkombinasikan beberapa model untuk mengurangi variance tanpa menambah bias secara signifikan.
Kesimpulan
Memahami dan mengelola bias serta variance adalah kunci dalam pengembangan model machine learning yang efektif. Dengan menggunakan teknik yang tepat untuk menyeimbangkan keduanya, kita dapat membangun model yang memiliki performa baik dan mampu melakukan generalisasi dengan baik terhadap data baru. Dengan demikian, model tidak hanya akan bekerja dengan baik pada data pelatihan tetapi juga pada data yang belum pernah dilihat sebelumnya.